
The FST Linking Engine: Linking NLP processed Text with Vocabularies indexed in a Solr index
The Lucene FST Linking Engine is an Entity Linking Engine based on the Lucene FST (Finite State Transducer) technology. FST provides a very efficient way to hold Entity labels in-memory. This avoids the need of disc IO for such as required by the other entity linking engines.
This engine is build on top of the OpenSextant Solr-Text-Tagger that implements the building of the FST models as well as the tagging of the processed text.
Configuration
The configuration of the FST linking engine consists of several parts explained in detail by the following sub-sections. Configurations can be created by using the Configuration Dialog provided by the Apache Felix Webconsole (search for "FST Linking" in the configuration tab). However NOTE that his dialog dos not include all supported configuration options. Options not included in the dialog can be configured by directly using OSGi configuration (*.config) files.
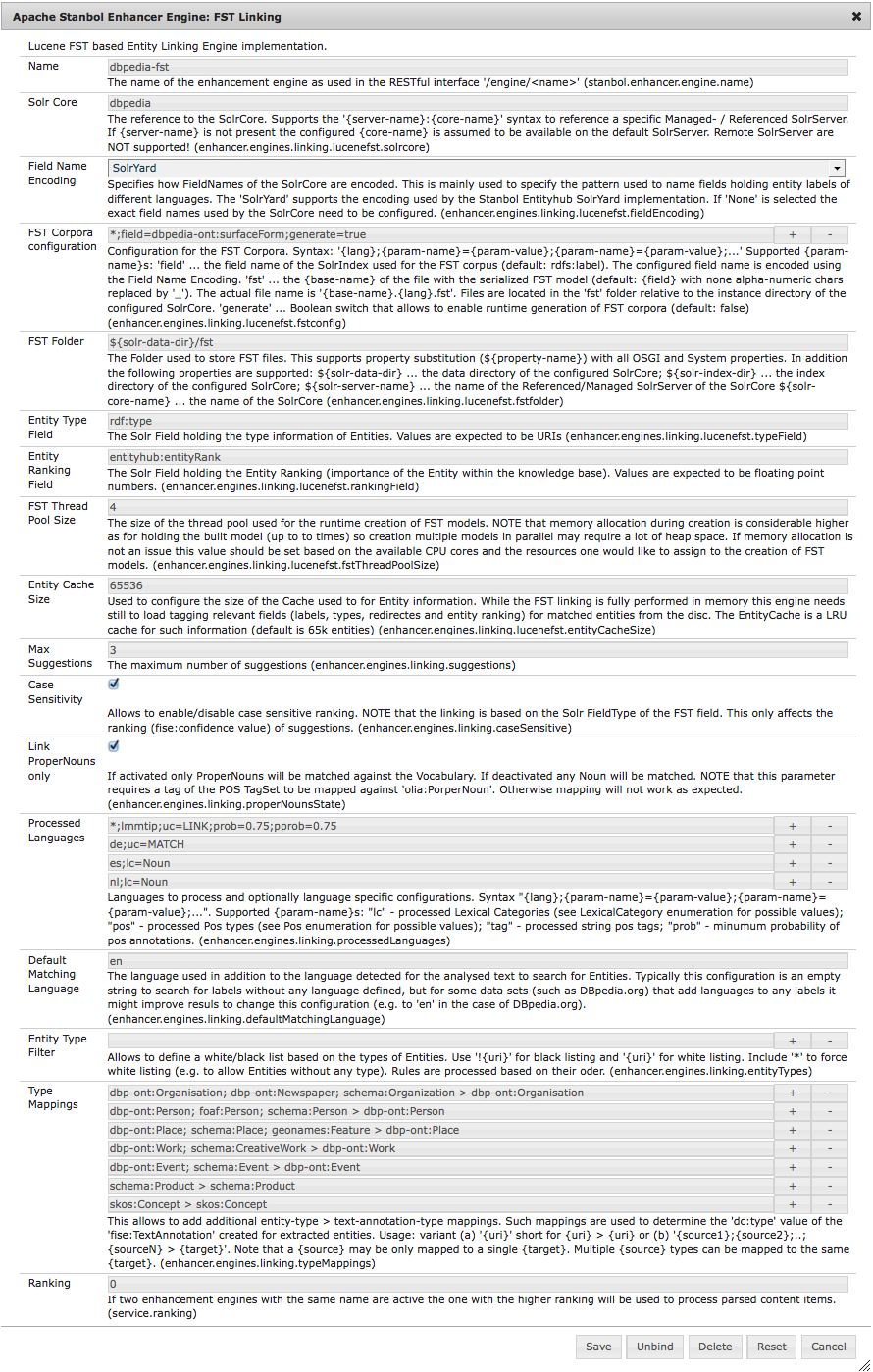{kind=link}
Engine Name and Service Ranking
As all Stanbol Enhancement Engines this engine support the following two properties
- Name (stanbol.enhancer.engine.name): The name of the Enhancement Engine. This name is used to refer an EnhancementEngine in EnhancementChains
- ServiceRankging (service.ranking): In case multiple enhancement engines do use the same name, than only the one with the higher ranking will get uses.
Configuration of the Solr Index

The Solr index is configured by using the enhancer.engines.linking.lucenefst.solrcore configuration property of the Engine. This property needs to point to a Solr index that runs embedded in the same JVM as Apache Stanbol. The Stanbol Commons Solr modules provide two Components that allow to configure embedded Solr Indexes:
- ReferencedSolrServer: This components allows uses to configure a directory containing a SolrServer configuration (the directory with the solr.xml file). All Solr indexes defined by the Solr.xml will be initialized and published as OSGI services to Apache Stanbol. Such indexes can be configured to the engine by using {server-name}:{index-name}. {server-name} is the name of the ReferencedSolrServer as provided in the configuration. {index-name} is the name of the Solr index as defined in the solr.xml.
- ManagedSolrServer: This component allows to have a Solr server that is fully managed by Apache Stanbol. Indexes can be installed by copying '{name-name}.solrindex.zip' files to the 'stanbol/datafiles'. Solr indexes initialized like that will be available under '{index-name}' and 'default:{index-name}'.
Used Solr indexes need also confirm to the requirements of the SolrTextTagger module. That means that fields used for FST linking MUST use field analyzers that produce consecutive positions (i.e. the position increment of each term must always be 1). This means that typical field analyzers as sued for searches will not work.
The SolrTextTagger README provides an example for a Field Analyzer configuration that does work. To make things easier this engine includes this XML file that includes a schema.xml fragment with FST tagging compatible configurations for most languages supported by Solr.
Solr Index Layout Configuration

This part of the configuration is used to specify the layout if the used Solr index. It specifies how Entity information are stored in the Solr index.
Field Name Encoding
The Field Name Encoding configuration enhancer.engines.linking.lucenefst.fieldEncoding specifies how Solr fields for multiple languages are encoded. As an example a Vocabulary with labels in multiple languages might use "en_label" for the English language labels and "de_label" for the German language labels. In this case users should set this property to UnderscorePrefix and simple use "label" when configuring the FST field name.
The Field Name Encodings work well with Solr dynamic field configurations that allow to map language specific FieldType specifications to prefixes and suffixes such as
This is the full list of supported Field encodings:
- SolrYard: This supports the encoding use by the Stanbol Entityhub SolrYard implementation to encode RDF data types and language literals. If you configure the FST Linking Engine for a Solr index build for the SolrYard you need to use this encoding
- MinusPrefix:
{lang}-{field}(e.g. "en-name") - UnderscorePrefix:
{lang}_{field}(e.g. "en_name") - AtPrefix:
{lang}@{field}(e.g. "en@name") - MinusSuffix:
{field}-{lang}(e.g. "name-en") - UnderscoreSuffix:
{field}-{lang}(e.g. "name_en") - AtSuffix:
{field}-{lang}(e.g. "name@en") - None: In this case no prefix/suffix rewriting of configured
fieldandstorevalues is done. This means that the FST Configuration MUST define the exact field names in the Solr index for every configured language.
FST Tagging Configuration

The FST Tagging Configuration enhancer.engines.linking.lucenefst.fstconfig defines several things:
- for what languages FST models should be build. This configuration is basically a list of language codes but also supports wildcards '*' and exclusions '!{en}'
- what fields in the Solr Index are used to build FST models. Two fields per language are required: a) an 'Indexed Field' (field parameter) and b) a 'Stored Field' (stored parameter). Both the indexed and stored field might refer to the same field in the Solr index. In that case this field needs to use
indexed="true" stored="true". - if FST models can be build by the Engine at runtime as well as the name of the serialized models.
This configuration is line based (multi valued) and uses the following generic syntax:
{language};{param}={value};{param1}={value1}; !{language}
{language} is either the name of the language (e.g. 'en'), '*' for all languages or '' (empty string) for defining default parameter values without including all languages. Lines that do start with '!' do explicitly exclude a language. Those lines do not allow parameters.
The following parameters are supported by the Engine:
- field: The indexed field in the configured Solr index. In multilingual scenarios this might be the 'base name' of the field that is extended by a prefix or suffix to get the actual field name in the Solr index (see also the field encoding configuration)
- stored (default: field value) : The field in the Solr index with the stored label information. This parameter is optional. If not present
storedis assumed to be equals tofield. - fst (default based on field value): This parameter allows to specify the name of the FST file stored within the FST directory (as configured by the [FST storage location]. The default name is generated by using the
fieldwith non alpha-numeric chars replaced by '_'). - generate (default: false): If enabled the Engine will generate missing FST models. If this is enabled the engine will also be able to update FST models after changes to the Solr Index. NOTE that the creation of FST models is an expensive operation (both CPU and memory wise). The FST engine uses a pool of low priority threads to create FST models. The size of the pool can be configured by using the
enhancer.engines.linking.lucenefst.fstThreadPoolSizeparameter. Because of this the default isfalse.
A more advanced Configuration might look like:
;field=fise:fstTagging;stored=rdfs:label;generate=true en de es fr it
This would set the index field to "fise:fstTagging", the stored field to "rdfs:label" and allow runtime generation. It would also enable to process English, German, Spanish, French and Italian texts. A similar configuration that would build FST models for all languages would look as follows
*;field=fise:fstTagging;stored=rdfs:label;generate=true
Linking Mode
The FST linking engine does support three different linking modes. Those are configures using the Linking Mode (enhancer.engines.linking.lucenefst.mode) property. The linking mode property is no longer part of the configuration form. as their are now three separate components with a specialized configuration for each linking mode.
The three modes are
PLAIN: This mode links the plain text with the vocabulary. Every single word of the text will get looked up with the vocabulary. This mode does not use NLP results other than language detection. Because of that this mode will ignore any Text Processing Configuration. The PLAIN mode works fine with smaller and specific vocabularies that do not only contain entities but also things like product ids, activities, adjectives ...LINKABLE_TOKEN: This mode links only linkable tokens of the parsed text. The provided Text Processing Configuration is used to determine linkable tokens in the text (based on NLP results). This is the default mode for this engine. It is well suited for vocabularies containing named entities (such as persons, cities, products, organizations, roles, ...)NER: This mode will only consider detected Named Entities for linking. This mode is similar to using the Named Entity Linking Engine. This is a best mode if the enhancement chain contains an NER component that can detect the types of entities contained in the linked vocabulary. Important for this mode is that Named Entity types can be mapped to types of Entities in the linked vocabulary. This allows to validate matching entities based on their type. Those mappings are configured by the Named Entity Type Mappings (enhancer.engines.linking.lucenefst.neTypeMapping) property.
The Named Entity Type Mappings uses the following syntax:
{named-entity-type} > {voc-type-1}[; {voc-type-2}; ...]
meaning that the Named Entities with the {named-entity-type} will only accept entities in the vocabulary with one of the {voc-type-1}, {voc-type-2}, ... types. Entities of other types that would match the mention of the Named Entities will get filtered.
An typical configuration could look like the following.
dbp-ont:Person > dbp-ont:Person; schema:Person; foaf:Person dbp-ont:Organisation > dbp-ont:Organisation; dbp-ont:Newspaper; schema:Organization dbp-ont:Place > dbp-ont:Place; schema:Place; geonames:Feature
NOTE: Also full URIs can be used
By default the FST linking engine uses the LINKABLE_TOKEN. In this mode this engine behaves similar as the Entityhub Linking Engine.
As mentioned before three OSGI components are provided for configuring FST linking engines with the different modes:

The Apache Stanbol Enhancer Engine: FST Linking: Linkable Token (org.apache.stanbol.enhancer.engines.lucenefstlinking.FstLinkingEngineComponent) is the default FstLinkingEngine component. It supports all configuration parameter. When not using the user interface it is strongly recommended to use this component for the configuration of the FST linking engine.
The Apache Stanbol Enhancer Engine: FST Linking: Plain (org.apache.stanbol.enhancer.engines.lucenefstlinking.PlainFstLinkingComponnet) can be used to configure a PLAIN mode linking engine. The form excludes any Text Processing Configuration property as those are anyway not used in the PLAIN mode.
The Apache Stanbol Enhancer Engine: FST Linking: Named Entities (org.apache.stanbol.enhancer.engines.lucenefstlinking.NamedEntityFstLinkingComponnet) is intended to allow the configuration of a FST linking engine in the NER mode. It includes the Named Entity Type Mappings (enhancer.engines.linking.lucenefst.neTypeMapping) property in the form. This is used to configure type mappings from the Named Entity types to types in the linked vocabulary.
Additional Entity Information

In addition to the URI and the labels of Entities the EntityLinking process also uses entity type and ranking information.
- Entity Type Field (enhancer.engines.linking.lucenefst.typeField): This field specifies the Solr field name holding entity type information of Entities. In case 'SolrYard' is used as Field Name Encoding one can use the the QNAME of the property (typically 'rdf:type'). Otherwise the value must be the exact field name holding the type information. Values are expected to be URIs.
- Entity Ranking Field (enhancer.engines.linking.lucenefst.rankingField): This is an ADDITIONAL property used to configure the name of the Field storing the floating point value of the ranking for the Entity. Entities with higher ranking will get a slightly better
fise:confidencevalue if labels of several Entities do match the text.
NOTE that type and ranking information are optional.
Runtime FST generation Thread Pool
The enhancer.engines.linking.lucenefst.fstThreadPoolSize parameter can be used to configure the size of the thread pool used for the runtime generation of FST models. The default size of the thread pool is 1. Threads do use the lowest possible priority to reduce the performance impact on enhancements as much as possible.
When configuring the size of the thread pool users need to be aware that the generation of FST models does need a lot more memory as the resulting model. So having to manny parallel threads might require to increase the memory settings of the JVM. On typical machines FST creation threads will consume 100% CPU. That means that the number of threads should be configured to the number of CPU cores that can be spared for FST generation.
NOTE that the generate parameter of the FST Tagging Configuration needs to be set to true to enable runtime generation.
FST storage location

FST models are not only kept in memory but also serialized to disc. This avoids rebuilding the model after a restart of the Stanbol Server. By default the models are stored within the data folder of the SolrCore. However in some scenarios users might want to store FST models in a different location. This can be achieved by using the enhancer.engines.linking.lucenefst.fstfolder property.
The configuration options does support property substitution with OSGI and System properties. In addition it supports the following additional properties (all relative to the configured SolrCore.
solr-data-dir: the data directory of the SolrCoresolr-index-dir: the index directory of the SolrCoresolr-server-name: the name of the ReferencedSolrServer or ManagedSolrServer holding the SolrCore (see also [Configuration of the Solr Index]solr-core-name: the name of the SolrCore
The default value of this property is '${solr-data-dir}/fst'. To manage FST models within the Stanbol folder you can us e.g. '${sling.home}/fst/${solr-server-name}/solr-core-name'.
Entity Cache Configuration
While FST tagging is fully done in-memory the FST linking engine needs to read information of matching Entities from the Solr index. This requires disc IO and is typically the part of the process that consumes the most time. The Entity Cache tries to prevent such disc level IO by caching SolrDocuments containing only fields required for the linking process (labels, types and (if available) entity rankings). To further reduce memory requirements only labels in languages requested by processed ContentItems are stored in the cache. The Cache uses the LRU semantic and is based on the Solr cache implementation.
The size of the cache can be configured by using the enhancer.engines.linking.lucenefst.entityCacheSize parameter. The default size is ~65k entities. Increasing the maximum size of the cache will improve performance.
TIP: For small and medium sized vocabularies the cache can be configured to be >= as the size of Entities in the Vocabulary. In this case the FST linking engine will full operate in-memory. For such scenarios linking was up to 100 times faster as with the Entityhub Linking Engine
Text Processing Configuration
With the extension of the SolrTextTagger with a TaggingAttribute the FST linking engine can support the exact same text processing functionality as the other Entity Linking Engine.
For the configuration please see the Text Processing configuration section of the Entity Linking Engine.
Entity Linking Configuration
The Entity Linking Configuration of this Engine is very similar as the one for the EntityLinking engine. The configuration does use the exact same keys, but it does not support all properties and some do have a slightly different meaning. In the following only the differences are described. For the all other things please refer to the linked section of the documentation of the EntityLinking engine.
Label Field (enhancer.engines.linking.labelField): The label field is IGNORED as the field holding the labels is anyway provided by the [FST Tagging Configuration]. That means that the field defined by the stored parameter is used. If the stored parameter is not present it fallbacks to the field parameter.Type Field (enhancer.engines.linking.typeField): This configuration gets IGNORED in favor of theenhancer.engines.linking.lucenefst.typeField. See the [Additional Entity Information] section for details.- Redirect Field (enhancer.engines.linking.redirectField): Note implemented. NOTE This might not be possible to efficiently implement. When those redirects need already be considered when building the FST models.
Use EntityRankings (enhancer.engines.linking.useEntityRankings): This configuration gets IGNORED. EntityRanking based sorting is enabled as soon as the Entity Ranking Field is configured.Lemma based Matching (enhancer.engines.linking.lemmaMatching): Not Yet implemented- Min Match Score (enhancer.engines.linking.minMatchScore): The FST linking engine uses Levenshtein distance between the mention in the text and the best matching label of an Entity. It only adds suggestions if the match is greater as the configured value. NOTE that this might filter suggestions of the FST for several reasons but typical reasons are stemming on short labels as well as case insensitive analyzers combined with case sensitive matching.
- Minimum Chunk Match Score (enhancer.engines.linking.minChunkMatchScore): Tags provided by FST linking are reduced if they do match less as the configured percentage of tokens in a chunk. Implemented as
TagClusterReducer.
In addition the following properties are IGNORED as they are not relevant for the FST Linking Engine:
Max Search Token Distance (enhancer.engines.linking.maxSearchTokenDistance)Max Search Tokens (enhancer.engines.linking.maxSearchTokens)Min Matched Tokens (enhancer.engines.linking.minFoundTokens)Min Text Score (enhancer.engines.linking.minTextScore)