
Overview about Apache Stanbol
Apache Stanbol provides a set of reusable components for semantic content management. It is important to note that Stanbol itself is NOT a semantic CMS. It extends existing CMSs with a number of semantic services.

While Apache Stanbol was built with CMS in mind it can also be used for e.g. web applications (tag extraction and suggestions, text completion in search fields); 'smart' content workflows (using several Stanbol semantic engines chained together) or email routing based on extracted entities/topics; etc.

Content Enhancement
Extracting information from content is the most common use case for Apache Stanbol. To achieve this, you use the RESTful API of the Stanbol Enhancer to send your content to Stanbol. The Enhancer now applies its Semantic Engines to analyze the content. Extracted information is represented as RDF and returned in the Response of the Enhancement Request. For more information about how to use the Stanbol Enhancer please see this Usage Scenario.
The enhancements can be used to improve search and navigation. Enhancement results can also be used to support content editors e.g. by suggesting tags or by allowing the editor to directly interact with entities mentioned in the text, as is shown in the following figure.
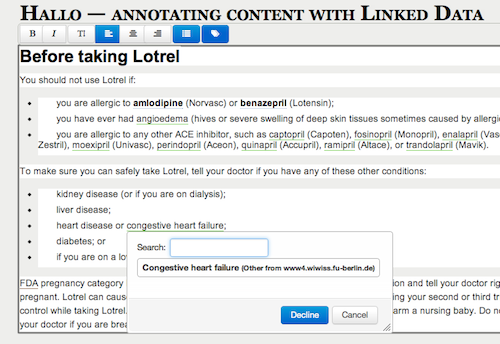
Detailed information on how to make use of the enhancement results returned by the Stanbol Enhancer are described in this usage scenario.
Customize Enhancement Results

Different application domains will have different needs for extracting entities from texts. Because of this Apache Stanbol can be customized with domain specific data as shown in the right hand figure (taken from life sciences).
For doing so you can either use the Stanbol Entityhub to manage your vocabulary or import existing data into the Entityhub. The usage scenario Working with Custom Vocabularies provides a detailed description about how to customize Apache Stanbol with application specific information.
As soon as the application specific information is available in Stanbol you can not only use it to extract information with the Stanbol Enhancer. You can also use it for:
- searching and exploring your domain knowledge using the Apache Entityhub RESTful services e.g. to get more/related information for entities extracted by the Stanbol Enhancer
- adding auto-completion to your UI by using VIE with the autocomplete widget
- using the Stanbol Entityhub together with Google Refine to clean-up and reconcile your data.
The Stanbol Enhancer can be configured to use custom vocabularies. This List of Enhancement Engines provides a good overview of the different configuration options. For specific semantic requirements you can also extend the Stanbol Enhancers by implementing your own Enhancement Engine.
Multilinguality
Apache Stanbol is built with multilinguality support in mind. While many components support multiple languages users need to be aware that not all features are available for all languages. Especially the Stanbol Enhancer depends on the availability of Natural Language Processing (NLP) functionality for given languages. Also the linking to Entities requires users to provide language-specific labels. For detailed information please see the usage scenario about Working with Multiple Languages.
Knowledge Models and Reasoning
TODO: Add features related to Knowledge Models and Reasoning.

Semantic Indexing and Search
TODO: add typical semantic search use cases
